Machine Learning may lead to unfairness
Evaluating causes of algorithmic bias in juvenile criminal recidivism
We have published an extended version of our ICAIL19 awarded paper in the Journal of AI and Law (paper). This is an interdisciplinary effort involving computer science (machine learning) and social sciences (decision making/psychology):
Marius Miron, Songül Tolan, Emilia Gomez, Carlos Castillo, “Evaluating causes of algorithmic bias in juvenile criminal recidivism”
We study the implication of using machine learning to predict reoffense risk of defendants in prison and we compare that with SAVRY, a structured professional risk assessment tool. In particular, we look at the causes of discrimination: differences in the prevalence of reoffense between protected groups (women vs men, foreigners vs non-foreigners), input/training features, and the machine learning model (neural network, logistic regression, svm etc.).
Note that in the ICAIL19 paper we show that ML methods can achieve better predictive performance than SAVRY but at the expense of unfairer outcomes. Furthermore, in comparison to ML tools which give a score, often with no explanation, SAVRY is not actuarial. It is completed by an expert and it is used to help the defendants improve on the problematic areas detected by a simple sum of scores.
With regards to the feature sets, we have a blog post from last year in which we explain the difference between SAVRY and Non-SAVRY features. Basically, SAVRY features are more related to things that the defendant can change, while Non-SAVRY features are related to demographics and personal history. In the ICAIL19 paper we show that using Non-SAVRY features yields better predictive performance and leads to more unfair outcomes than using SAVRY features.
For this paper, as well as in ICAIL19, we use the Catalonian data on juvenile recidivism and SAVRY. You can find the link to these data in the paper.
We equalize base rates (prevalence) between a reference group (non-foreigners or men) and the other groups (foreigners or women). There are a few ways to do this. We choose to oversample the non-reference groups by repeating in the dataset more people who have recidivated or not in order to match the prevalence of the reference group (EBR). This is a simple way of transforming the data and we compare it with a pre-processing mitigation: LFR (Zemel et al. 2013). LFR is based on an optimization procedure which transforms the data with respect to a protected feature (e.g. race) by removing any information about membership with respect to the protected group.
There are a few ways to measure algorithmic discrimination. In the paper we look at false positive rate disparity (FPRD) and false negative rate disparity (FNRD). For example, a FPRD for foreigners of 2 means that foreigners are twice as likely to be wrongfully classified as recidivists. Similarly, a FPRD for foreigners of 0.5 means that non-foreigners are twice as likely to be wrongfully classified as non-recidivists.
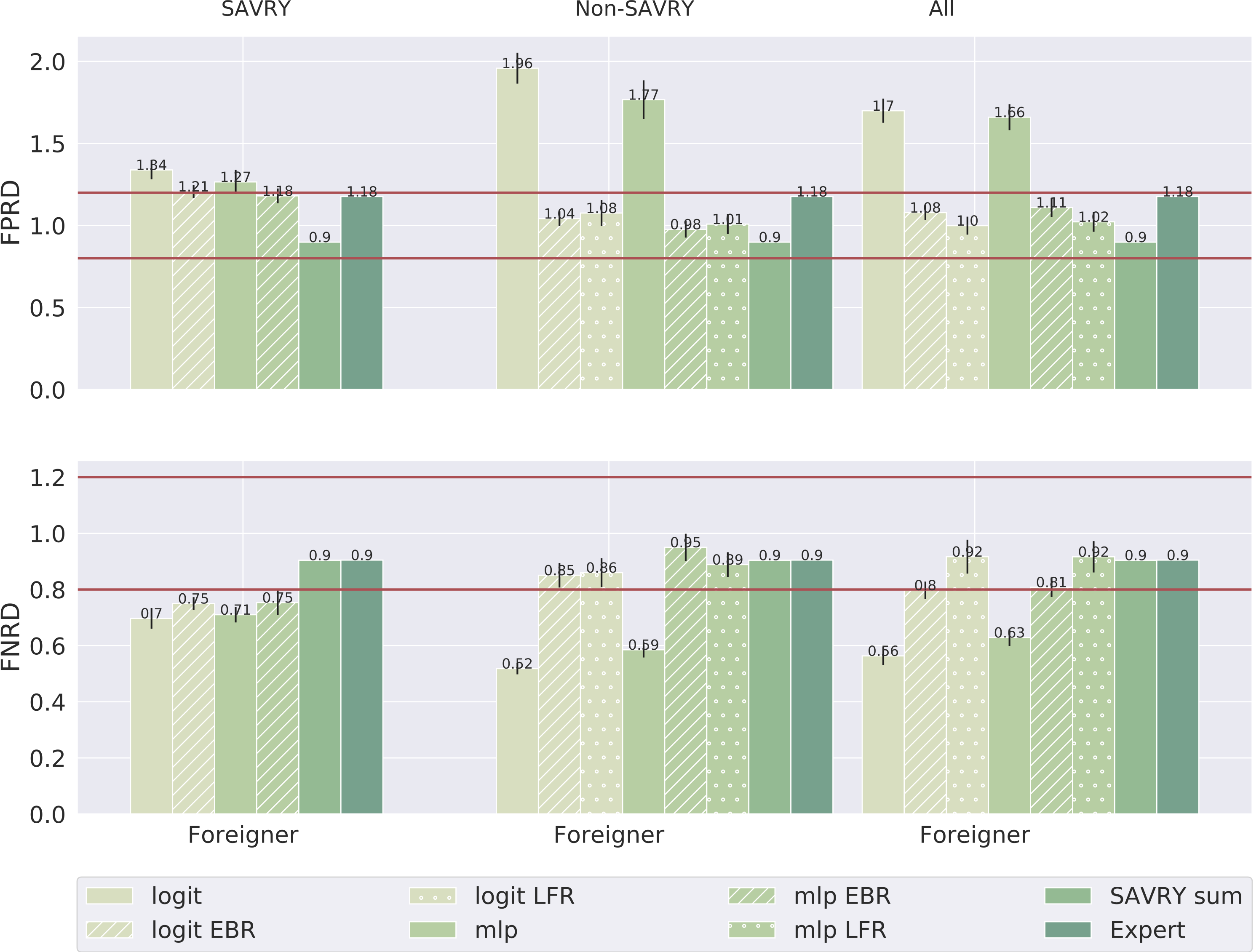
In the plots we compare EBR, LFR and the baseline (e.g. not doing any transformation on the data) for foreigners with respect to non-foreigners using the feature sets SAVRY, Non-SAVRY and All (their combination).
EBR, ensuring that the base rates are equal between foreigners and non-foreigners in the training data (both groups have the same prevalence of recidivism) reduces this disparity at a similar level with LFR. Moreover, EBR and LFR are effective when using features correlated with recidivism, like the demographic and personal history features present in the Non-SAVRY feature set. Furthermore, we see that the baseline often yields disparity which is not observed for the SAVRY Sum (the simple sum of SAVRY scores) and the Expert evaluations.
What is the impact of equalizing base rates on the area under the curve (AUC)? We found something interesting here: when effective in terms fairness, EBR and LFR experience a drop in terms of AUC: 0.01 for EBR and 0.06 for LFR. For the SAVRY feature set, EBR and LFR are not effective in reducing disparity and their AUC does not drop. In this case, there is a clear trade-off between predictive performance and fairness.
What if we use EBR? It’s simple, it reduces disparity, it doesn’t lose so much in terms of AUC. Well, first of all we use EBR with respect to a protected feature, e.g. foreigner. There is nothing ensuring that it will be fair with respect to sex, national groups, or any other protected feature that we care about. Moreover, by doing mitigation (LFR and EBR) you may end up discriminating even more with respect to other groups or even with under-represented sub-groups (e.g. you may discriminate against the Maghrebi subgroup of the foreigners group)!
Second, using LIME we looked at which features are important for EBR, LFR, and the baseline. With the exception of the SAVRY feature set, ML relies on demographic and personal history features. While doing EBR does not change much, the top 10 important features LFR are mostly SAVRY features.
- Baseline:
- Foreigner 242.83 13.82
- Sex* 233.00 22.87
- National group* 221.75 13.98
- Province of residence* 192.16 13.21
- No. of maincrimes* 167.58 9.87
- Age maincrime* 167.92 11.23
- Province of execution* 165.53 9.38
- Maincrime program sentence* 163.08 7.74
- No. of prior crimes* 167.63 12.34
- Maincrime program duration*
- EBR on attribute “nationality”
- Foreigner* 228.52 18.53
- National group* 213.45 12.75
- Sex* 218.75 21.10
- Province of residence* 187.01 13.35
- No. of prior crimes* 155.59 8.86
- No. of maincrimes* 155.28 9.76
- Province of execution* 152.80 8.04
- Maincrime program* 152.35 8.99
- Age maincrime* 157.60 15.19
- Maincrime program duration*
- LFR on attribute “nationality”
- Antisocial behaviour 123.50 18.96
- Attention deficit hyperactivity 123.29 18.85
- Anger management issues 122.70 18.39
- Treatment susceptibility 122.58 18.30
- High interest in school/work 123.38 19.20
- Pro-social support (by adult) 122.10 18.13
- Substance abuse 122.50 18.64
- Personality 122.54 18.73
- Family dynamics 122.38 18.66
- Positive/resilience characteristics 121.59 17.95
The star symbol denotes Non-SAVRY features which are mostly related to demographic and personal history features.
Now, rememeber that LFC experienced more AUC drop than EBR. This means that we can’t have good predictive performance and fair outcomes on this problem using machine learning. LFR as our most fair option (in terms of ML) has similar or worse AUC to the simple SAVRY sum of scores or Expert evaluation (human-in-the-loop). Note that in comparison to SAVRY sum, LFR cannot be fair with respect to all protected features (foreigner and sex). Mitigation itself is problematic in this case.
In conclusion, discrimination in ML for juvenile recidivism prediction can be explained partially by the difference in base rates. In addition, the nature of features used for training matters: SAVRY vs Non-SAVRY. Having features correlated with demographics and personal history may accentuate discrimination. Moreover, there are some differences between the ML algorithms, which point out that the ML algorithms may pick of different things when classifying someone as recidivist/non-recidivist.
So the question that policy makers ask themselves is why replace SAVRY with ML under these conditions? What are the areas that are of high risk?
There is a trend in computer science to advocate for neutrality of technology. However, as science in itself is neutral, there is a grey zone in computer science which contains applications which are far from neutral. Take for instance face recognition with all its inherent biases. Recently, companies as Microsoft and Amazon discontinued their work and support on this area. In my opinion, face recognition is just an application of image classification, and the way it has been designed and evaluated had a lot to do and did not care at all about the ethical implications and biases. Which makes me think whether these applications should be designed at all.
BLOG
research, news, machine learning, fairness, bias